Optimizing Neural Networks for Edge Devices
The deployment of neural networks on edge devices presents unique challenges due to the limited computational resources, memory constraints, and power limitations of these devices. This article explores various techniques for optimizing neural networks to run efficiently on edge devices while maintaining acceptable levels of accuracy.
The Challenge of Edge Deployment
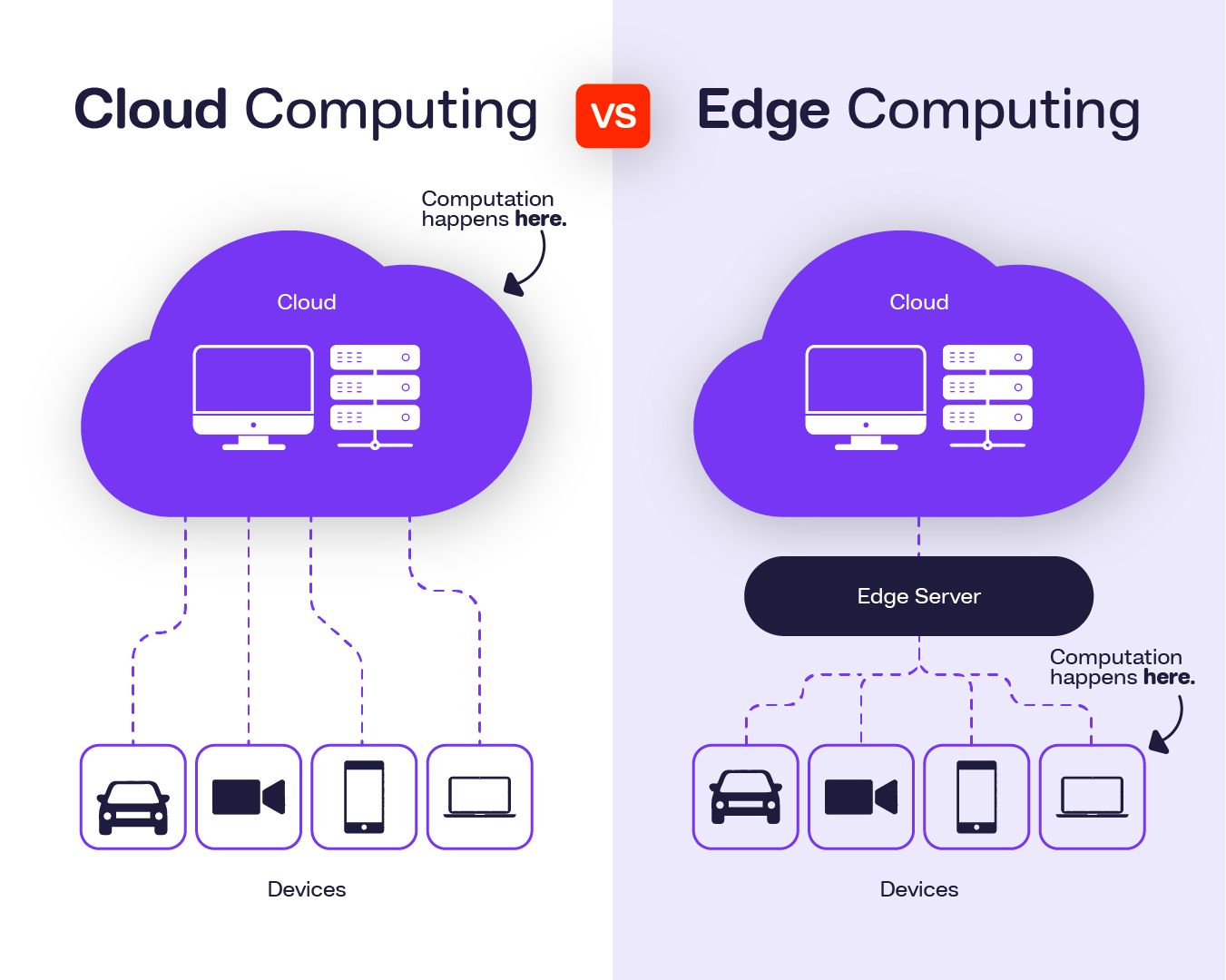
Edge devices, such as smartphones, IoT sensors, and embedded systems, typically have limited computational capabilities compared to cloud servers or dedicated GPU workstations. Deploying neural networks on these devices requires careful optimization to ensure real-time performance and energy efficiency.
Key Optimization Techniques
Here are the primary techniques for optimizing neural networks for edge devices:
- Model Pruning: Removing unnecessary connections and neurons
- Quantization: Reducing the precision of weights and activations
- Knowledge Distillation: Training smaller models to mimic larger ones
- Architecture Search: Finding efficient network architectures
- Operator Fusion: Combining multiple operations to reduce memory transfers
Model pruning is a technique that involves removing unnecessary connections and neurons from a neural network. This can significantly reduce the model size and computational requirements without substantial loss in accuracy. Research has shown that many neural networks are overparameterized, and a large percentage of weights can be pruned without affecting performance.
# Example of weight pruning in PyTorch
import torch
def prune_model(model, pruning_threshold):
for name, param in model.named_parameters():
if 'weight' in name:
mask = torch.abs(param.data) > pruning_threshold
param.data *= mask
return modelQuantization involves reducing the precision of the weights and activations in a neural network. For example, converting 32-bit floating-point numbers to 8-bit integers can reduce memory requirements and improve computational efficiency, especially on hardware that supports integer operations.
Quantization-aware training can reduce model size by 4x with minimal accuracy loss, making it one of the most effective optimization techniques for edge deployment.
Knowledge distillation is a technique where a smaller model (the student) is trained to mimic the behavior of a larger model (the teacher). This allows the smaller model to achieve performance closer to the larger model while being more suitable for edge deployment.
Case Study: MobileNet
MobileNet is a family of efficient neural network architectures designed specifically for mobile and edge devices. It uses depthwise separable convolutions to reduce the computational cost and model size while maintaining reasonable accuracy for image classification tasks.
The key innovation in MobileNet is the replacement of standard convolutions with depthwise separable convolutions, which factorize a standard convolution into a depthwise convolution and a pointwise convolution. This reduces the computational cost and number of parameters significantly.
# Depthwise Separable Convolution in PyTorch
class DepthwiseSeparableConv(nn.Module):
def __init__(self, in_channels, out_channels, stride=1):
super(DepthwiseSeparableConv, self).__init__()
self.depthwise = nn.Conv2d(in_channels, in_channels, kernel_size=3,
stride=stride, padding=1, groups=in_channels)
self.pointwise = nn.Conv2d(in_channels, out_channels, kernel_size=1)
def forward(self, x):
x = self.depthwise(x)
x = self.pointwise(x)
return xFuture Directions
The field of neural network optimization for edge devices is rapidly evolving. Future research directions include hardware-aware neural architecture search, where the network architecture is optimized specifically for the target hardware platform, and the development of specialized neural network accelerators for edge devices.
As edge AI continues to grow in importance, the development of more efficient neural network architectures and optimization techniques will remain a critical area of research and development.